エコモット社内では、昨年から技術者向けに何度かニューラルネットワークや分析の勉強会をしています。
現実的には、技術者より非技術者(管理とか営業とか企画とかとか、プログラマーやSEではないという意味)の方が何らかの分析すべきデータを持っていて、資料の作成から何かしらの判断まで様々なレベルでデータを活用するという業務上の必要性が多く存在しているように思われます。すでにBIツールや統計ツールなどを活用する人もいて、近年ブームになっているディープラーニングを活用したいというニーズは間違いなく、この層にも訪れると考えられます。
エコモットでは、技術者以外もディープラーニング技術を活用してもらいたいと思い、2月に非技術者向け勉強会を開催しました。また、同様の内容を圧縮し、株式会社インサイトテクノロジー様が主催するSapporo Tech Bar #17にて発表させていただきました。(本ブログは、これらのまとめを兼ねたダイジェストです。)
ディープラーニングって凄い人しかできないんじゃないの?
今までディープラーニングをやるということは、ほぼほぼTensorflowとかChainerとか・・・とかとかのフレームワークを使ってプログラムを作ることと同義でした。しかし、ソニーのNeural Network Consoleがこの状況を一変させようとしています。(そうに違いない!)
ソニー Neural Network Consoleとは
2017/8/17にソニーネットワークコミュニケーションズ株式会社からNeural Network Console(以下、NNC)がリリースされました。NNCは商用クォリティーのニューラルネットワーク構築ツールです。Windows版とクラウド版があります。以下のような特徴があります。
- ドラッグ&ドロップによる簡単編集
- 構造自動探索
- すぐに学習、すぐに結果を確認
- 学習の履歴を集中管理
詳細は公式サイトを参照してください。
このNNCを活用すれば、非技術者には縁遠い、環境構築やプログラミングなしにディープラーニングの世界を堪能できるようになります。ソニーネットワークコミュニケーションズ株式会社に感謝!
日経平均を使って予想してみた
とは言え、チュートリアルあるある的なアヤメとかワイン品質とか手書き文字とか・・・普通の人には味気なく興味がわきにくいデータたちでは、今までやらなかった精神的なハードルが超えられるとは到底思えません。そこで、思い切って日経平均株価の予想することにしました。(興味わきましたかね?)
日経平均日次データの当日を含む過去5営業日分を使って、翌日を予測することをターゲットにして、ライブで分析します。(勉強会はライブデモ&実習形式でしたが、ブログ内では雰囲気でw)
日経平均データ
日経平均プロフィル-日経の指数公式サイト-にあるダウンロードセンターから日経平均株価の日次データをダウンロードして使います。
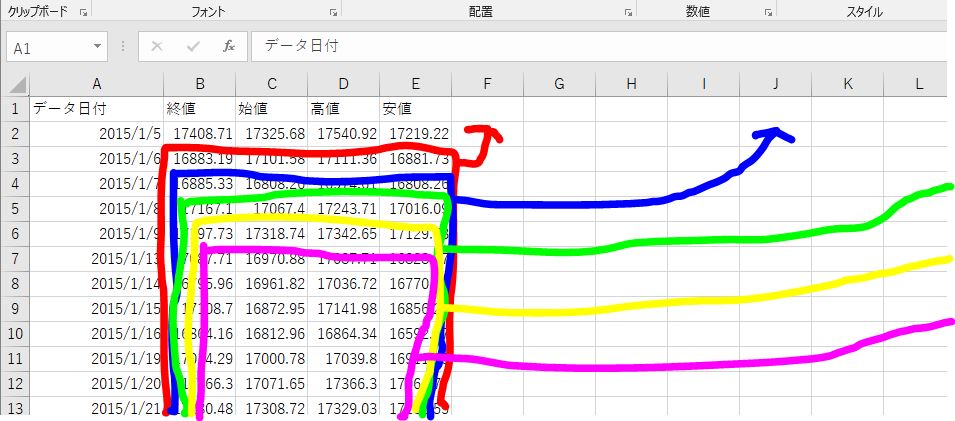
2015年1月5日からダウンロードした時までの年月日、終値、始値、高値、安値がCSV形式で保存されています。
教師データの作成
今回は2018/3/13にダウンロードした783レコードを利用しました。
まず、nikkei_stock_average_daily_jp.csvをダブルクリックすると、大抵の人はエクセルが立ち上がると思いますので、以下の要領で入力する5日分のデータと出力(正解)の1日分のデータを作成します。
- 1/6以降の全データをコピー(1/6の終値のところに合わせて、CTRL+SHIFT+右カーソル、CTRL+SHIFT+下カーソル、CTRL+C)
- 1/5の安値の左隣のセル(F2のセル)にフォーカスし、ペースト(CTRL+V)
- 1/7以降の全データをコピー
- 1/5の行の最右側にペースト
- 同様に1/13以降のデータまで繰り返します。(この時点でY列まで埋まればOKです。)
- 入力値のラベルを付け。終値とラベルされているところにx__0(エックス、アンダーバー、アンダーバー、ゼロ)と入力し、その左以降は、x__1、x__2・・・、x__19としてください
- 正解値のラベル付け。x__19の右隣りをy__0とし、y__1、y__2、y__3と入力します。(ここで、データとラベルがそろっているか確認しておいてください)
- データ不足の行を消します。Y列データの一番下に移り、その下の行にあるすべてのデータ(A780:Y785)を消します。
- 日付の列を削除(左方向にシフト)
- 保存
- 保存したファイルをコピーし、複製を作る
- 一つをtraning.csv、もう一つをtest.csvとリネームする
- traning.csvを開き、601行目以降の全データを削除し保存する。(599レコード。全体の8割程度)
- test.csvを開き、2行目から600行目の全データを削除(上方向にシフト)し保存する。(184レコード。全体の2割程度)
これで、訓練データと評価データのセットが完成しました。日本語のパスやファイル名だと後々エラーになりますので、ドキュメントフォルダー(ここは日本語に見えますが、実際はDocumentsなので、大丈夫)の下に日本語文字を使わないフォルダー(例えば、nk225)を作り、そこに保存しておいてください。
NNCを起動する。
ちなみに、NNCをダウンロードしたら、zipを展開すればインストールは終わりです。
neural_network_console.exeをダブルクリックすると起動します。
起動したら、利用規約に同意し、+New Projectをクリックしたら、EDITタブが開きます。
まずは順伝搬型ニューラルネットワークから
入力層、隠れ層、出力層の3層ネットワークから始めたいと思います。ネットワークは、左端のコンポーネントリストからネットワークグラフにドラッグ&ドロップすることで、構築できます。図のようにつなげればOKです。
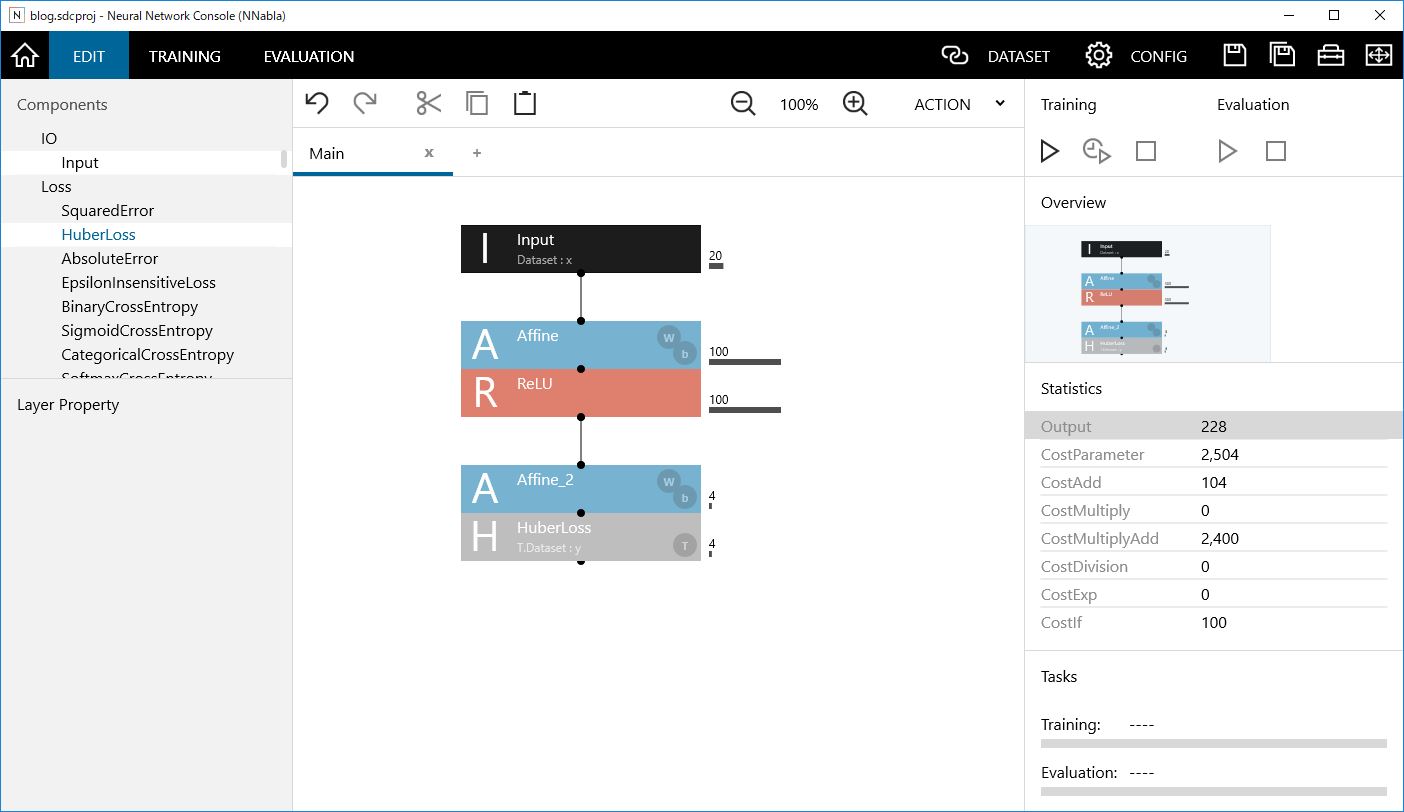
次に、各種パラメータを設定します。このままではデータの入出力ができませんので、入力層と出力層のサイズを変更します。
Inputをクリックすると、左下のパラメータのSizeがデフォルト値の1,28,28になっていると思います。これを20とします。次に出力層のAffineをクリックし、OutShapeが100になっているところを4にします。これで、入力ノードが20で、出力ノードが4になりました。
次にデータを読み込みます。DATASETタブをクリックし、画面が切り替わったら、ImageNormalizationのチェックを外し、DATASETタブの真下にある四角矢印のアイコンをクリックします。
先ほど作ったtraining.csvを選択します。
次に、左側にあるValidationの枠をクリックし、再びImageNormalizationのチェックを外し、DATASETタブの真下にある四角矢印のアイコンをクリックし、先ほど作ったtest.csvを選択します。
これで、データの準備は整いましたので、プロジェクトのファイルを保存します。(CONFIGの右隣りにあるフロッピーアイコンで保存できます。とりあえず、nikkei225とします)
学習開始
右側のTrainingの下にある再生ボタン風なアイコンを押してください。(F5でもOK)
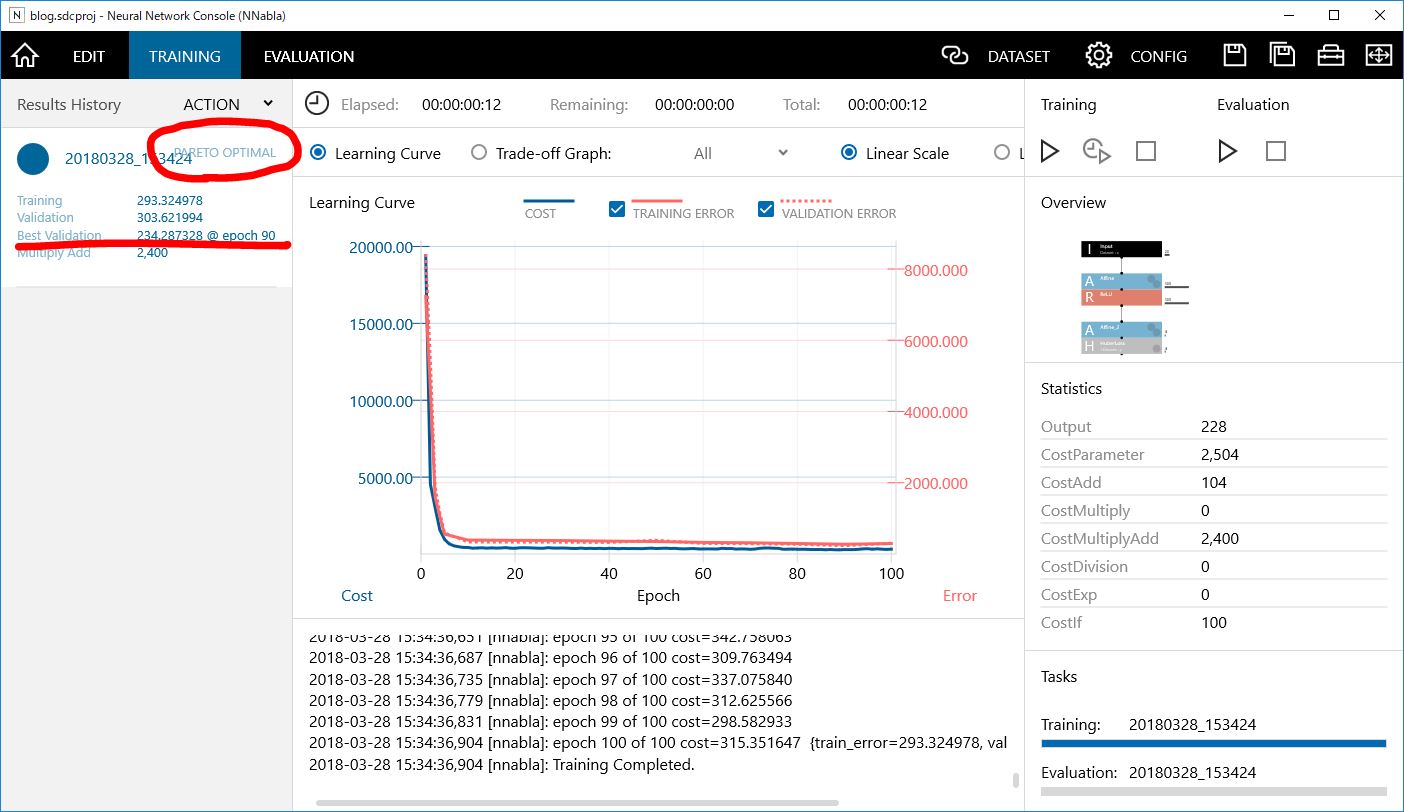
トレーニングタブの中に学習曲線のグラフが生成されてきたら成功です。全く同じにはなりませんが似たような感じになると思います。PARETO OPTIMALとの表示(パレート最適)は学習がいい感じにできていることを表しています。また、Best Validationの値は評価データと予測値との平均二乗誤差を表し、小さいほど誤差が小さいことになります。この誤差を見ながら、ニューラルネットワークを改良していくことになります。
Evaluationタブを開き、右側にあるEvaluationの再生ボタン風のアイコンをクリックして、評価しましょう。
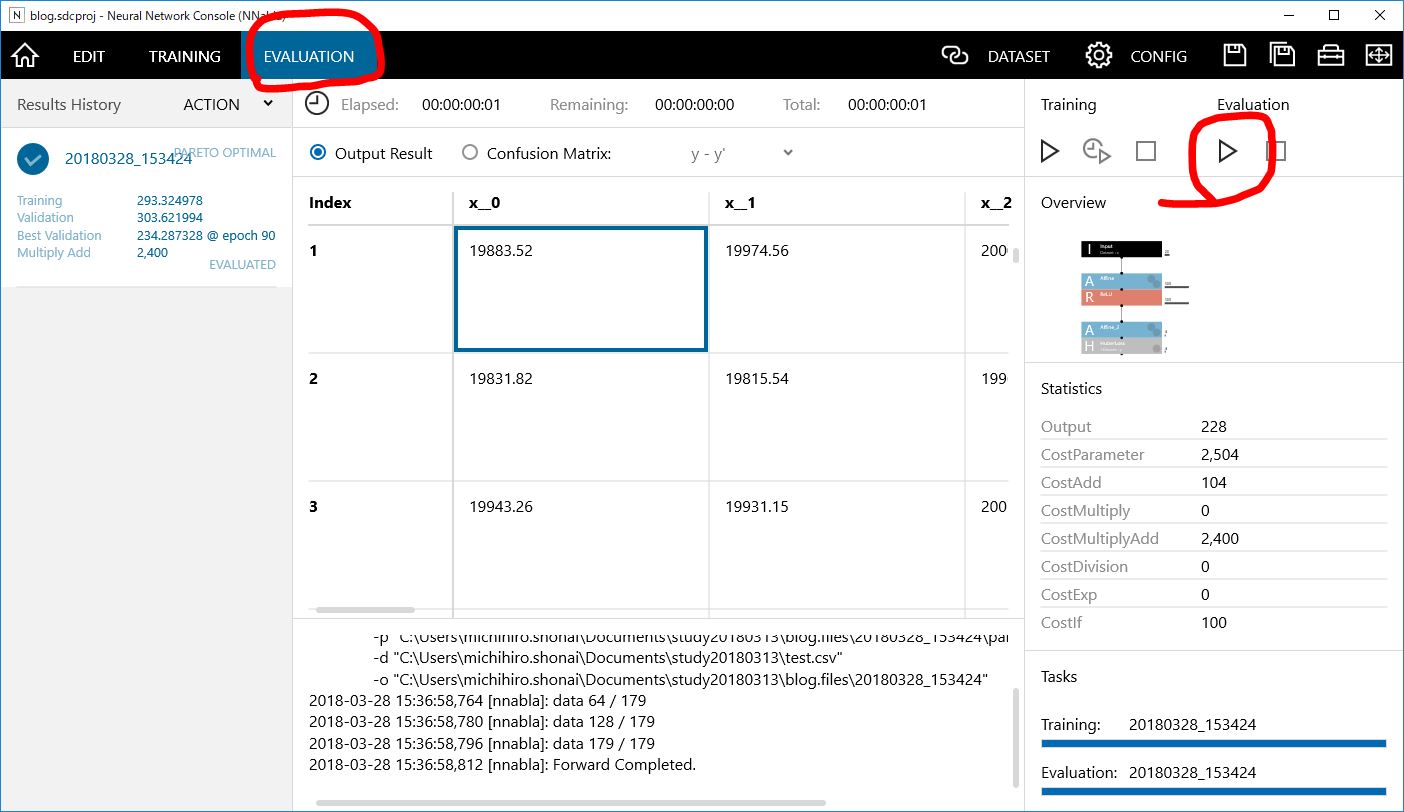
すぐにデータが出力されたと思います。ここで、このデータを右クリックして、メニューからSAVE CSV as…でデータを保存します。(ここではffnn_eva.csvとします)
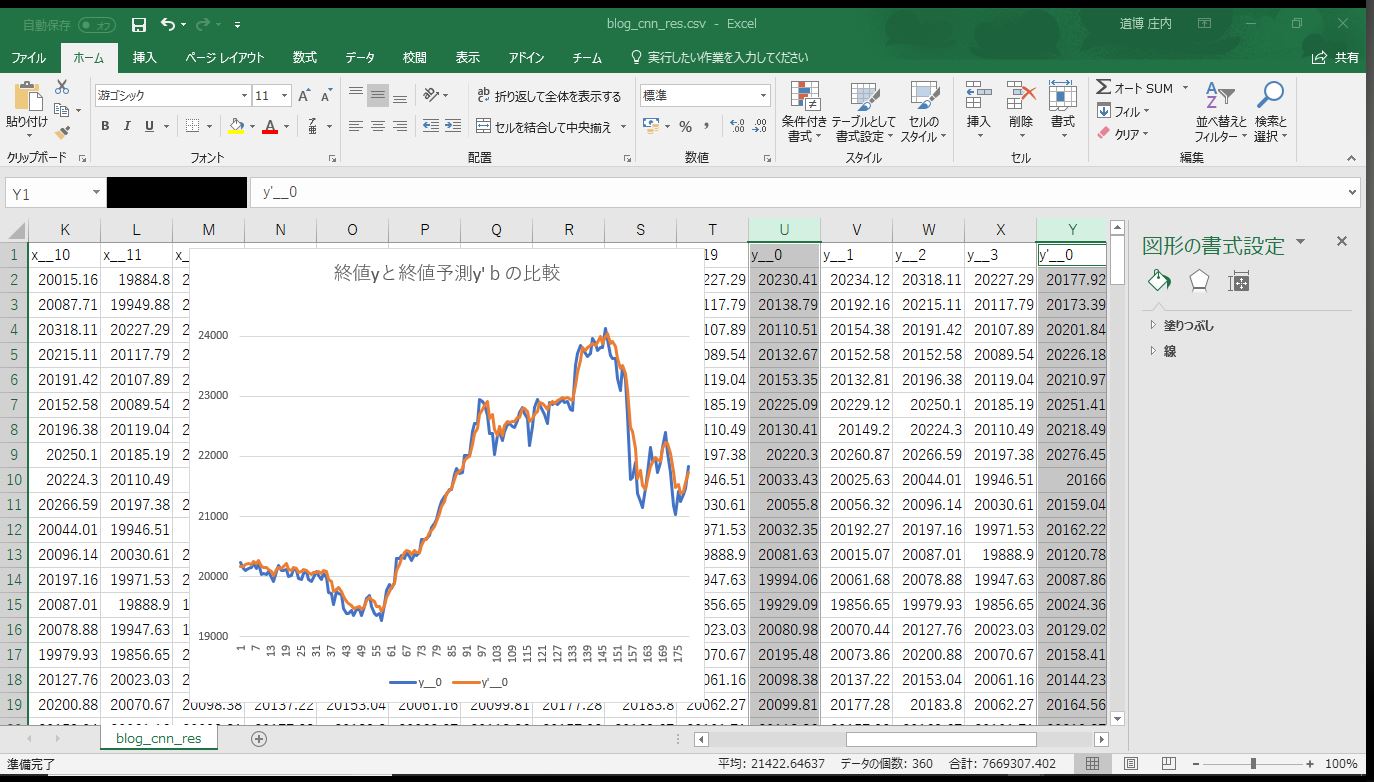
このファイルをエクセルで開き、終値と終値予測(y__0とy’__0)のデータをグラフにしてみましょう。
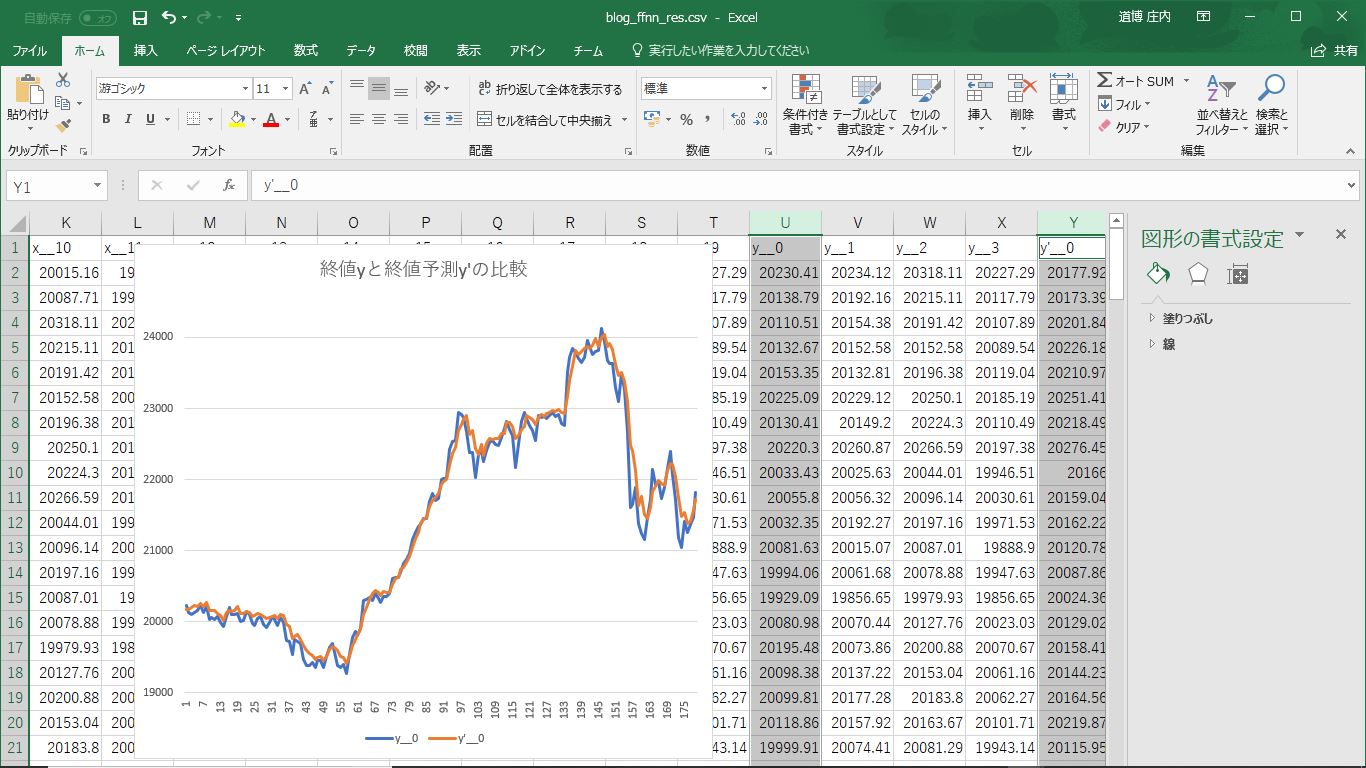
結構あってますね。隠れ層を増やしたり、隠れ層のノードを増やすなどして、いろいろ試してみてください。
次にCNNしましょう
CNNとは畳み込みニューラルネットワークのことで、画像認識などで利用されるネットワークです。グラフの形も何かの画像に見えなくもありません。そういう構造的な特徴を学習してくれることを期待しつつ、うまくいくかやってみましょう。
入力層のサイズは20でしたが、4項目の5日分を1枚の画像として取り扱うために、Reshapeで変形します。OutShapeは、1,5,4となります。
中間の隠れ層部分を消して、Convolution+ReLU層にします。とりあえず、Convolutionのkernelサイズは縦に3、横に2とします。kernelのところを3,2としてください。これは、横方向が終始と高安の2組の関係性になっている事からの発想です。
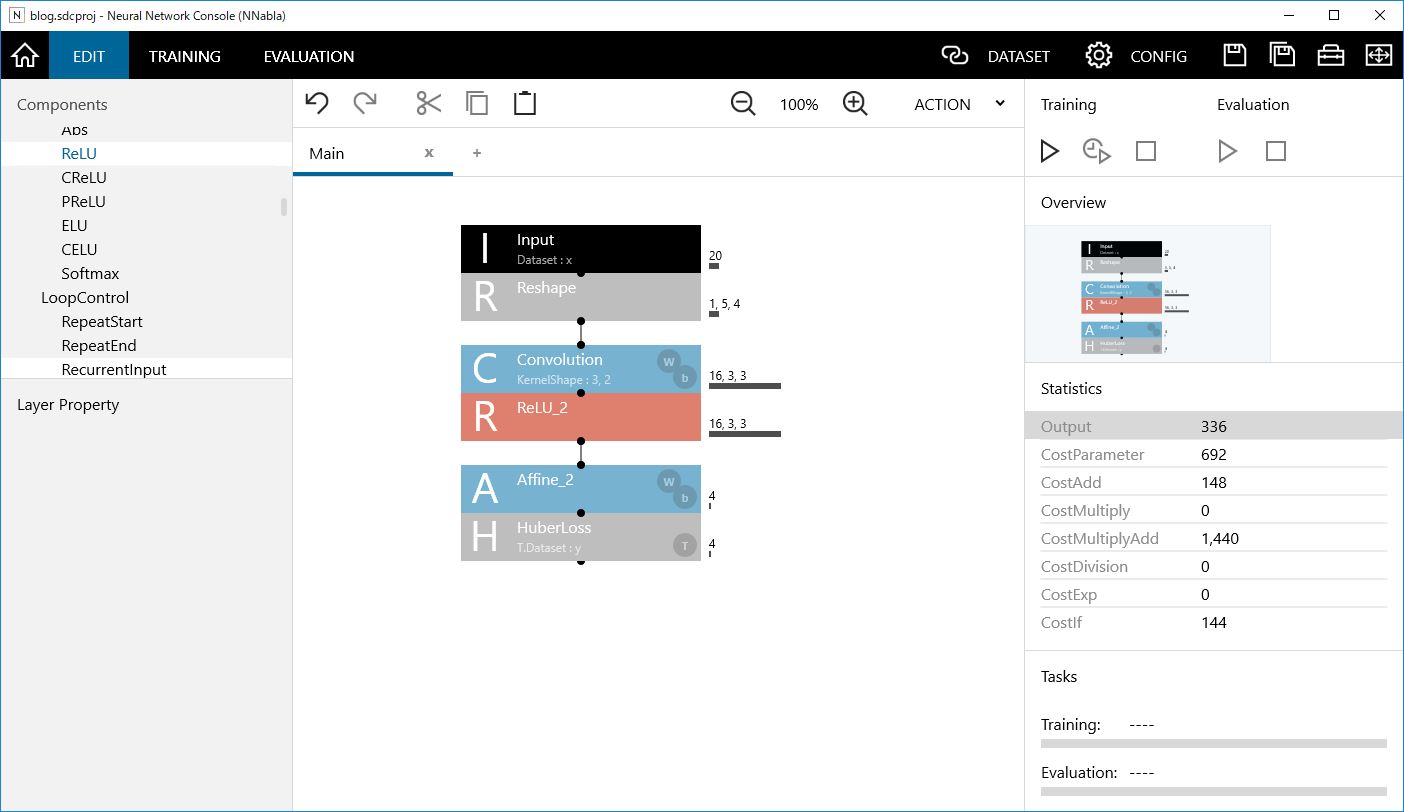
学習・評価してみましょう。先ほどとあまり変わらない数値になったと思います。ただし、CNNの方が計算量の指標であるMultiplyAddが3割以上少なくなっています。それだけ計算が軽くなっていることになります。
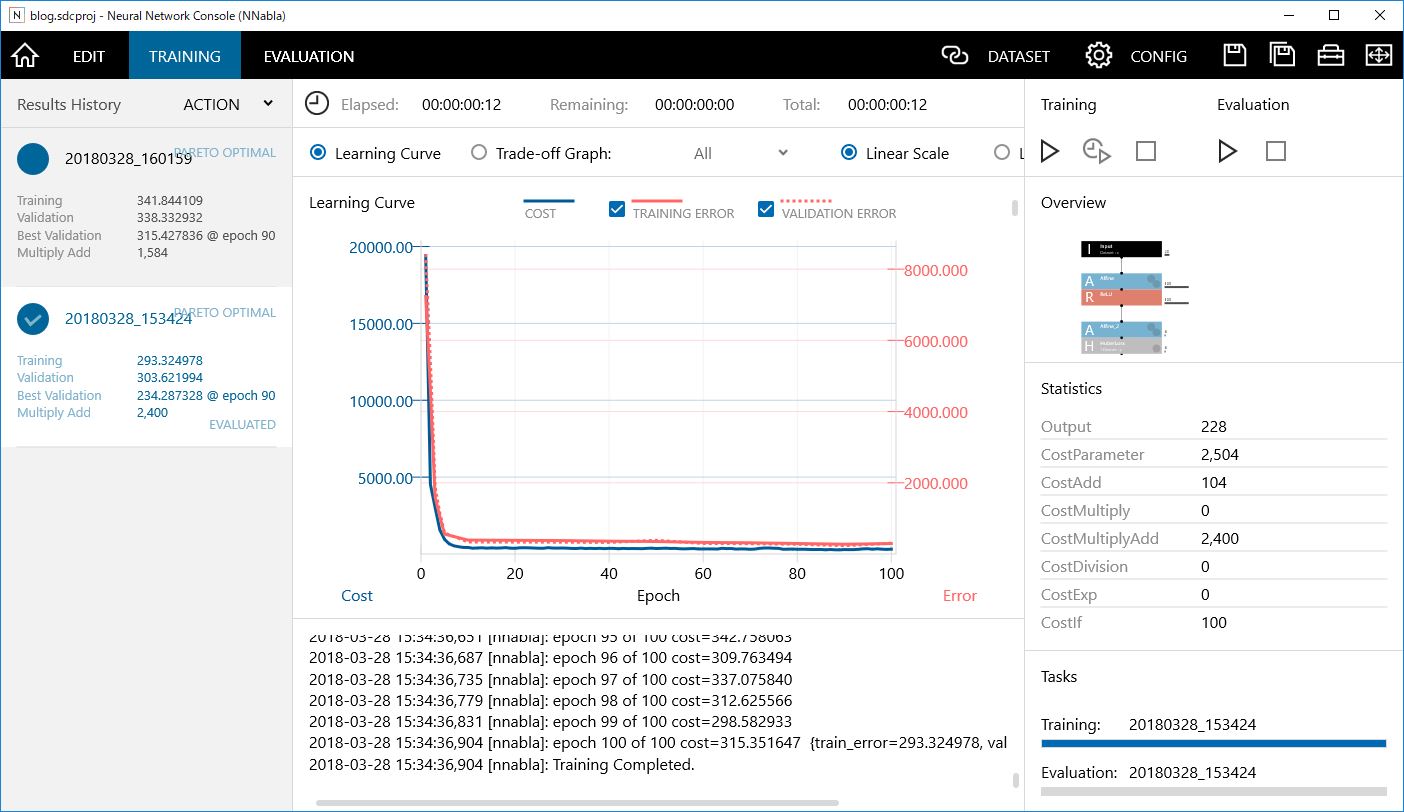
過学習
学習曲線のグラフで、赤の実線が訓練データとのエラー曲線で、赤の点線が評価データとのエラー曲線です。この実線と点線が学習が進むにつれてワニ口のように開いていく状態を過学習と呼びます。訓練データだけ過剰に適合し、評価データには適合しなくなった状態です。
今回の学習曲線を見ると、まだ過学習にはなっていません。ということはもっと学習回数を増やすことができそうです。
学習回数(Epoch数)を増やす
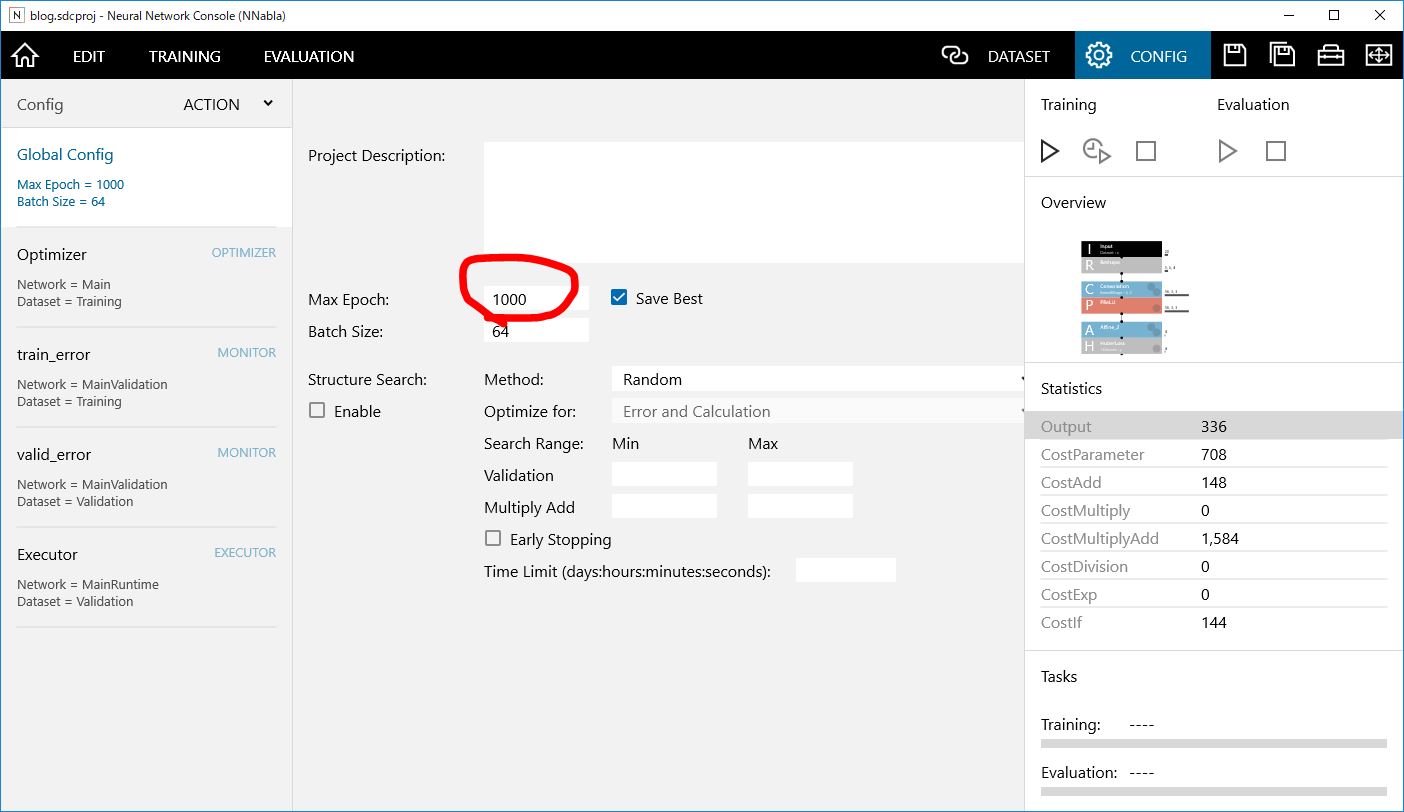
configタブを開き、MaxEpochを100から1000にして、学習してみましょう。1000にしても過学習は起こっていないようです。学習回数が増えたことで、BestValidationの値も小さくなったと思います。
評価を実行し、エクセルでグラフを書くとかなりフィットしていることが確認できます。ちなみに平均二乗誤差が88.09でしたので、平方根をとると平均で約±9.4円の精度で再現できていることになります。(わかる人にしかわからないけど地味に凄いんですw)
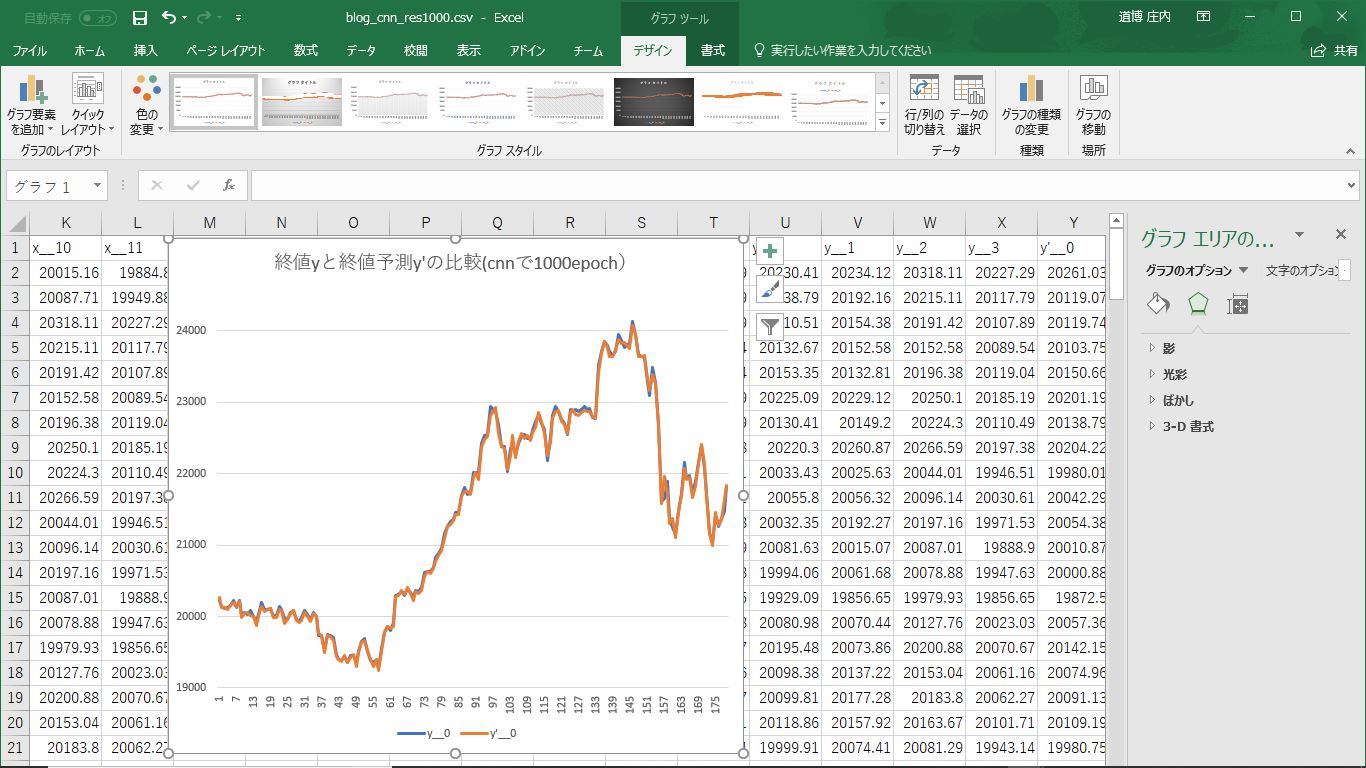
この予測値をどのように使うかとかそこら辺はお約束の自己責任でお願いします。
まとめ
ソニーNeuralNetworkConsoleは簡単に使えて、すぐにディープラーニングがはじめられます。
ディープラーニングはどうしてそうなるかという説明がし難くなるものの見て頂いた通り驚くほど強力です。どうしてそうなるかわからなくていいから予測や分類を利用したい方は試してみてはいかがでしょうか?
詳しくは附属のマニュアルを参考にしてください。